回看过去几个月,RunWay的Gen-2、Pika Lab的Pika 1.0,国内大厂等视频生成模型纷纷涌现,不断迭代升级。
这不,RunWay一大早就宣布Gen-2支持文本转语音的功能了,可以为视频创建画外音。

当然,谷歌在视频生成上也不甘落后,先是与斯坦福李飞飞团队共同发布了W.A.L.T,用Transformer生成的逼真视频引来关注。

今天,谷歌团队又发布了一个全新的视频生成模型VideoPoet,而且无需特定数据便可生成视频。

最令人惊叹的是,VideoPoet一次能够生成10秒超长,且连贯大动作视频,完全碾压Gen-2仅有小幅动作的视频生成。
另外,与领先模型不同的是,VideoPoet并非基于扩散模型,而是多模态大模型,便可拥有T2V、V2A等能力,或将成为未来视频生成的主流。
在文本到视频的转换中,生成的视频长度是可变的,还可以根据文本内容展现出多种动作和风格。
左:一艘船在波涛汹涌的海面上航行,周围是雷电交加的景象,以动态油画风格呈现
对于视频风格化,VideoPoet先预测光流和深度信息,然后再将额外的文本输入到模型。


如下,首先从模型中生成2秒钟的动画片段,然后在没有一点文本引导的情况下尝试预测音频。这样就能从一个模型中生成视频和音频。
通常情况下,VideoPoet以纵向的方式生成视频,以便与短片视频的输出相一致。
具体文本比编排上,研究人员要求Bard先写一个关于一只旅行浣熊的短篇故事,并附带场景分解和提示列表。然后,为每个提示生成视频片段,并将所有生成的片段拼接在一起,制作出下面的最终视频。

扩展:一个由水构成的行走的人。背景中有闪电,同时从这个人身上散发出紫色的烟雾

当前,Gen-2、Pika 1.0视屏生成的表现足以惊人,但是遗憾的是,无法在连贯大幅动作的视频生成上表现惊艳。
对此,谷歌研究人员提出了VideoPoet,能够执行包括文本到视频、图像到视频、视频风格化、视频修复/扩展和视频到音频等多样的视频生成任务。
相比起其他模型,谷歌的方法是将多种视频生成功能无缝集成到单一的大语言模型中,而不依赖针对各个任务分别训练的专用组件。
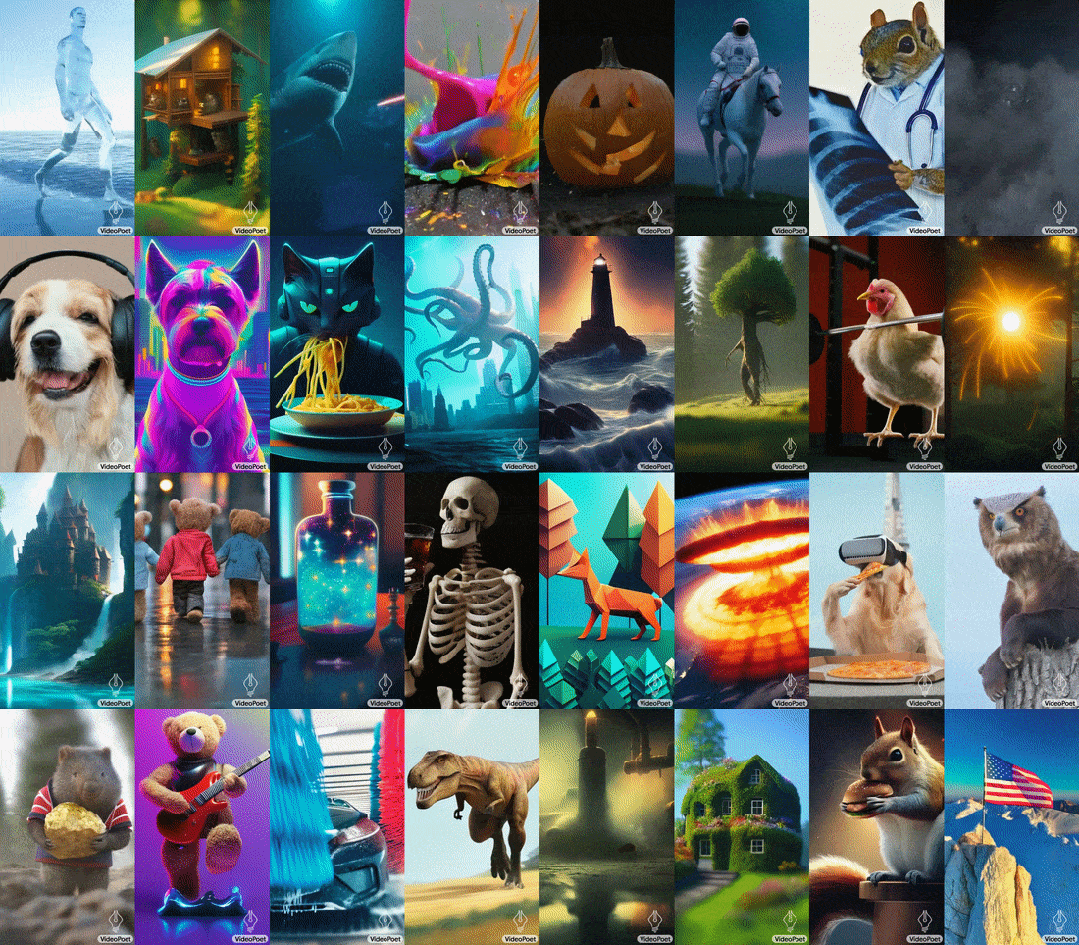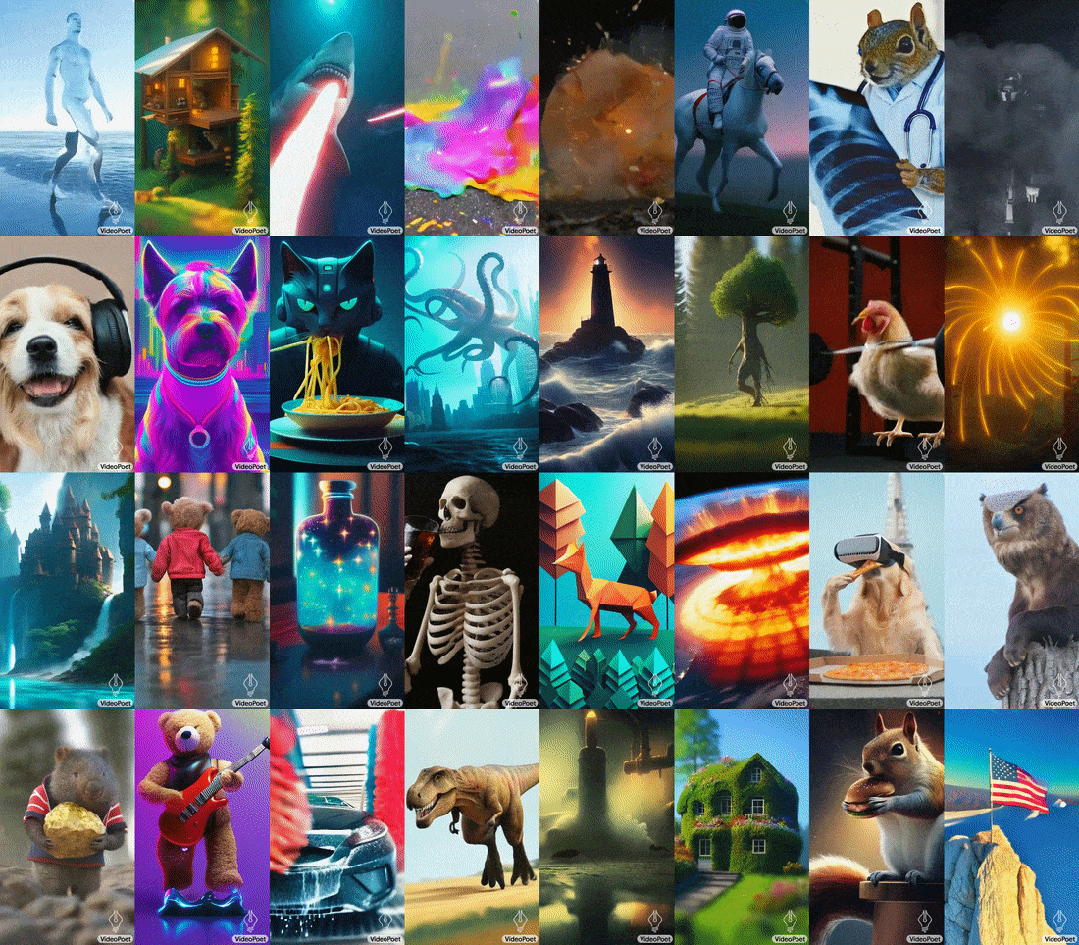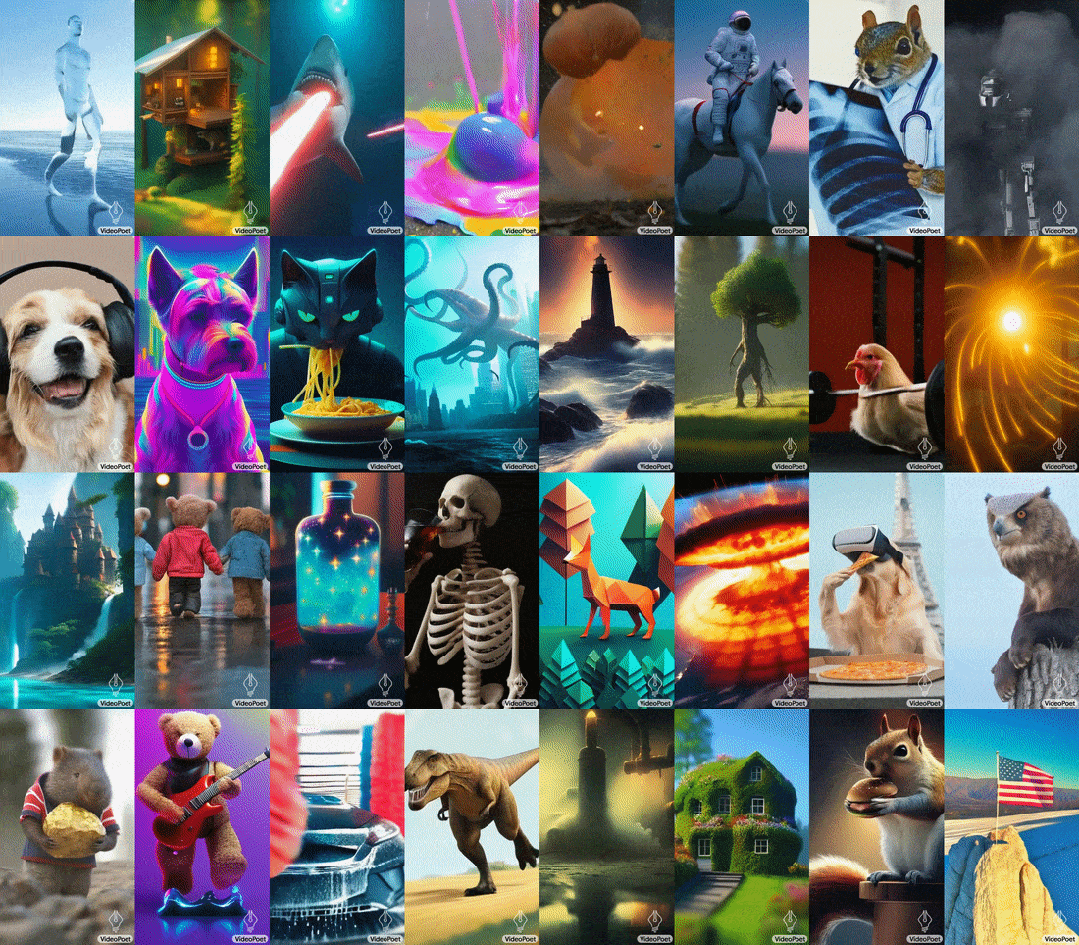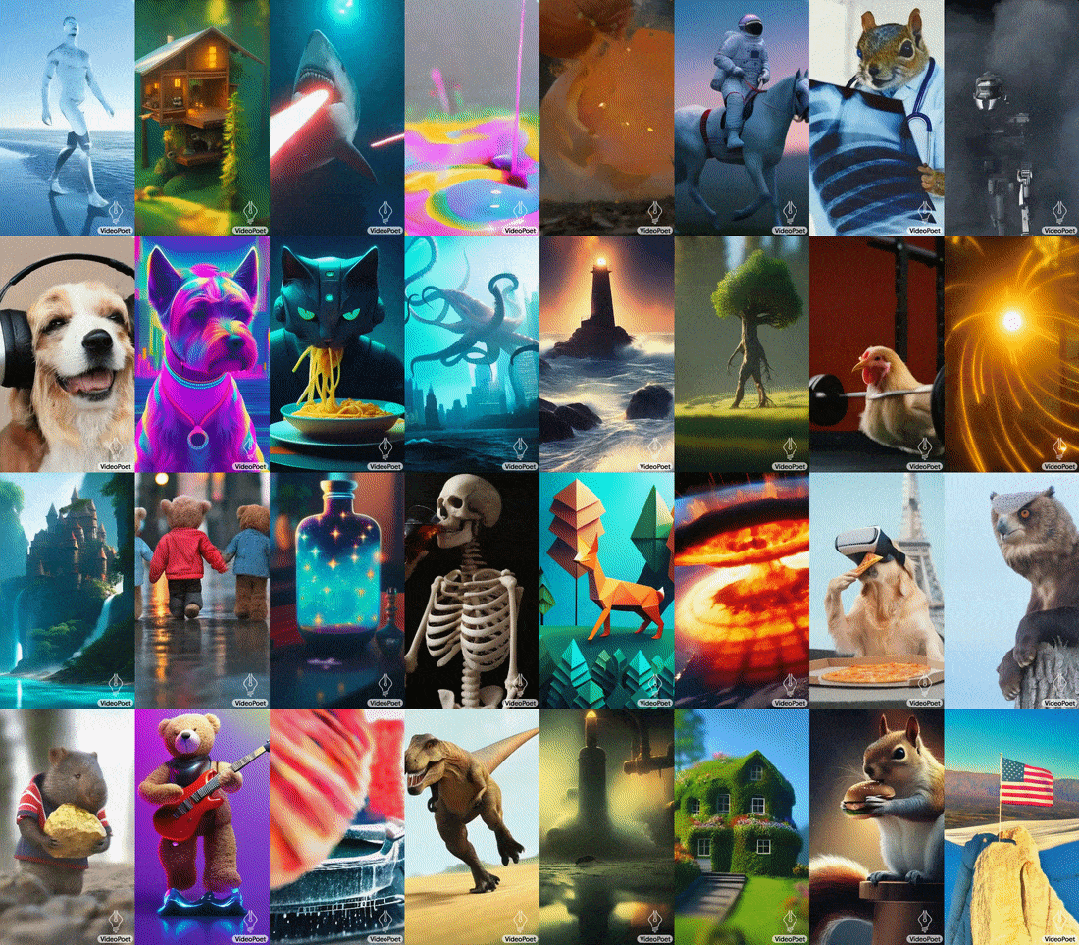
- 预训练的MAGVIT V2视频tokenizer和SoundStream音频tokenizer,能将不同长度的图像、视频和音频剪辑转换成统一词汇表中的离散代码序列。这些代码与文本型语言模型兼容,便于与文本等其他模态进行结合。
- 自回归语言模型可在视频、图像、音频和文本之间进行跨模态学习,并以自回归方式预测序列中下一个视频或音频token。
- 在大语言模型训练框架中引入了多种多模态生成学习目标,包括文本到视频、文本到图像、图像到视频、视频帧延续、视频修复/扩展、视频风格化和视频到音频等。此外,这些任务可以相互结合,实现额外的零样本功能(例如,文本到音频)。
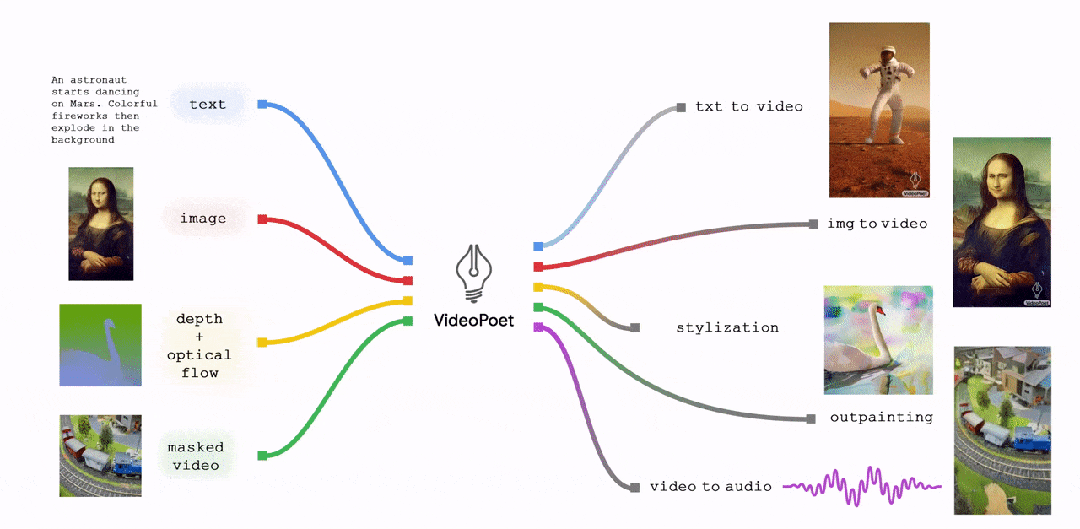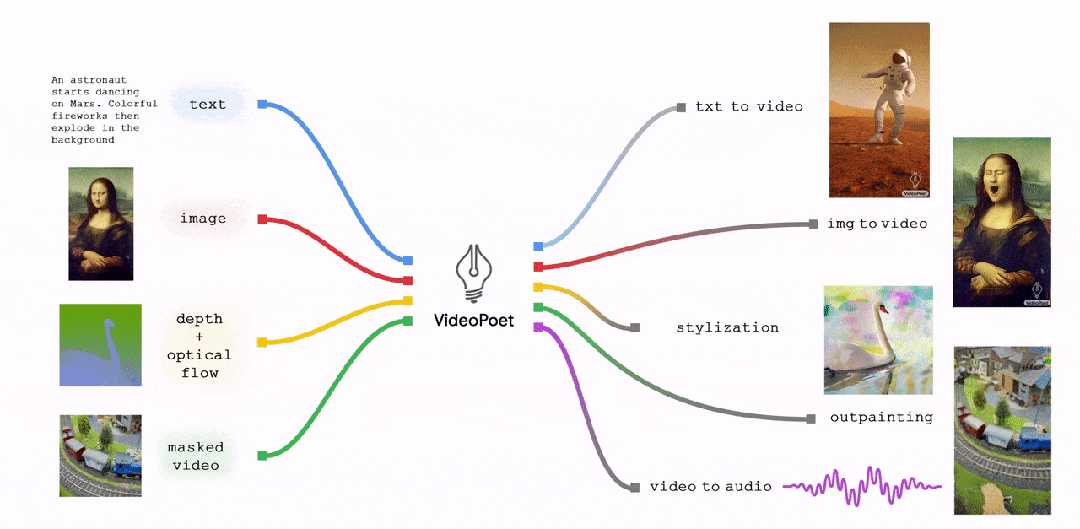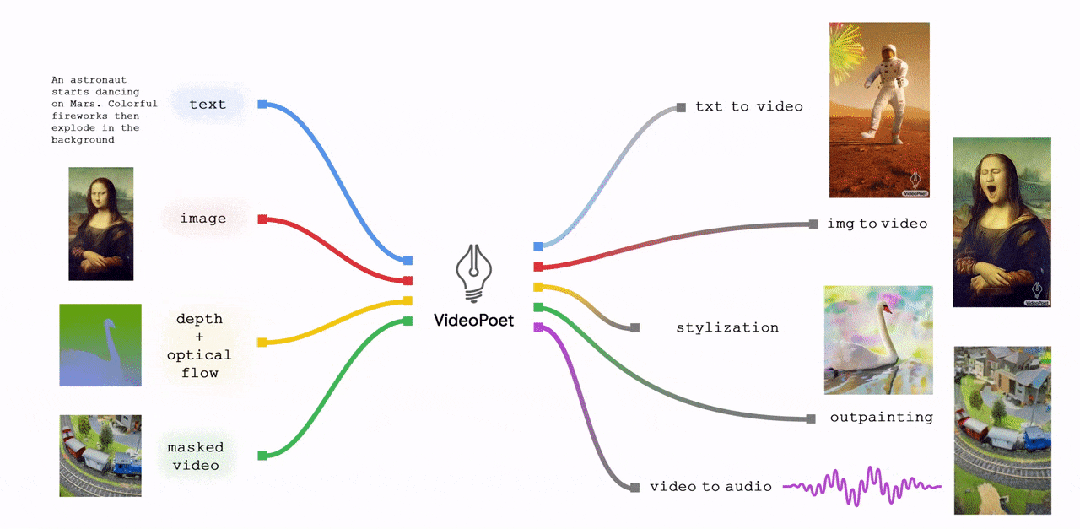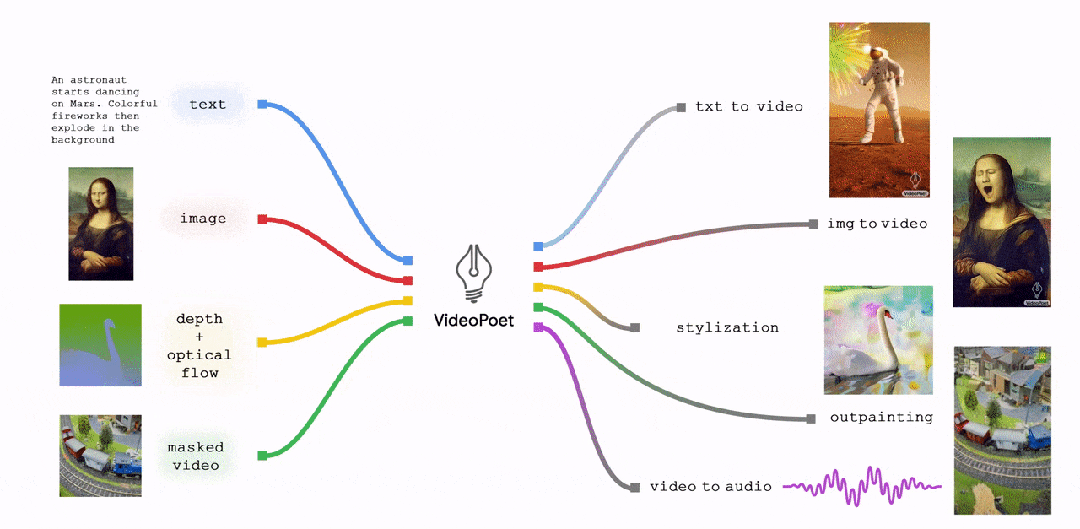
VideoPoet能够在各种以视频为中心的输入和输出上进行多任务处理。其中,LLM可选择将文本作为输入,来指导文本到视频、图像到视频、视频到音频、风格化和扩图任务的生成
使用LLM进行训练的一个关键优势是,可以重用现有LLM训练基础设施中引入的许多可扩展的效率改进。
幸运的是,视频和音频tokenizer,可以将视频和音频剪辑编码为离散token序列(即整数索引),并可以将其转换回原始表示。
VideoPoet训练一个自回归语言模型,利用多个tokenizer(用于视频和图像的MAGVIT V2,用于音频的SoundStream)来跨视频、图像、音频和文本模态进行学习。
一旦模型根据上下文生成了token,就能够正常的使用tokenizer解码器将这些token转换回可查看的表示形式。

VideoPoet任务设计:不同模态通过tokenizer编码器和解码器与token相互转换。每个模态周围都有边界token,任务token表示要执行的任务类型
概括来说,VideoPoet比起Gen-2等视频生成模型,具备以下三大优势。
VideoPoet通过对视频的最后1秒进行调节,并预测接下来的1秒,就可以生成更长的视频。
通过反复循环,VideoPoet通不但可以很好地扩展视频,而且即使在多次迭代中,也能忠实地保留所有对象的外观。

右:无人机拍摄的丛林中一座非常尖锐的精灵石城,城中有一条湛蓝的河流、瀑布和陡峭的垂直悬崖
相比于其他只能生成3-4秒视频的模型,VideoPoet一次就可以生成长达10秒的视频。

视频生成应用一个很重要的能力在于,对于生成的动态效果,用户有多大的控制能力。
VideoPoet不仅能为输入的图像通过文字描述来添加动态效果,并通过文本提示来调整内容,来达到预期的效果。

针对最左边的小浣熊跳舞视频,用户都能够通过文字描述不同的舞姿来让它跳不同的舞蹈。

如果我们提供一个输入视频,就可以改变对象的运动来执行不同的动作。对物体的操作可以以第一帧或中间帧为中心,从而实现高度的编辑控制。
「一个可爱的锈迹斑斑的破旧蒸汽朋克机器人的特写,机器人身上长满了青苔和新芽,周围是高高的草丛」。
对于前3个输出,没有提示动作的自主预测生成。最后一个视频,是在提示中添加了「启动,背景为烟雾」以引导动作生成。

VideoPoet还能够最终靠在文本提示中,附加所需的运镜方式,来精确控制画面的变化。
例如,研究人员通过模型生成了一幅图像,提示为「冒险游戏概念图,雪山日出,清澈河流」。下面的示例将给定的文本后缀添加到所需的动作中。

为了确保评估的客观性,谷歌研究人员在在各种提示上运行所有模型,并让人们对其偏好进行评分。


综上可见,平均有24-35%的人认为VideoPoet生成的示例比其他模型更加遵循提示,而其他模型的这一比例仅为8-11%。
此外,41%-54%的评估者认为VideoPoet中的示例动作更有趣,而其他模型只有11%-21%。
对于未来的研究方向,谷歌研究人员表示,VideoPoet框架将会实现「any-to-any」的生成,比如扩展文本到音频、音频到视频,以及视频字幕等等。
网友不禁发问,Runway和Pika能否抵挡住谷歌和OpenAI即将推出的文本到视频创新技术?

